使用人工智能的企业正面临一个重大挑战:延迟。当客户不得不等待聊天机器人处理他们的电子商务退货、被卡在抖动、延迟的游戏或阅读比动作慢几秒钟的电视字幕时,他们会感到沮丧。
进入边缘 AI。这项强大的技术通过分布式服务器网络将 AI 处理(称为推理)物理上移近用户,从而最大限度地减少延迟。通过减少延迟,边缘 AI 克服了这些客户挫败感,为选择边缘 AI 的企业带来了竞争优势。在本文中,我们将介绍边缘推理的三个用例:游戏资产、自动字幕和副标题以及聊天机器人。
边缘 AI 让玩家留在游戏中
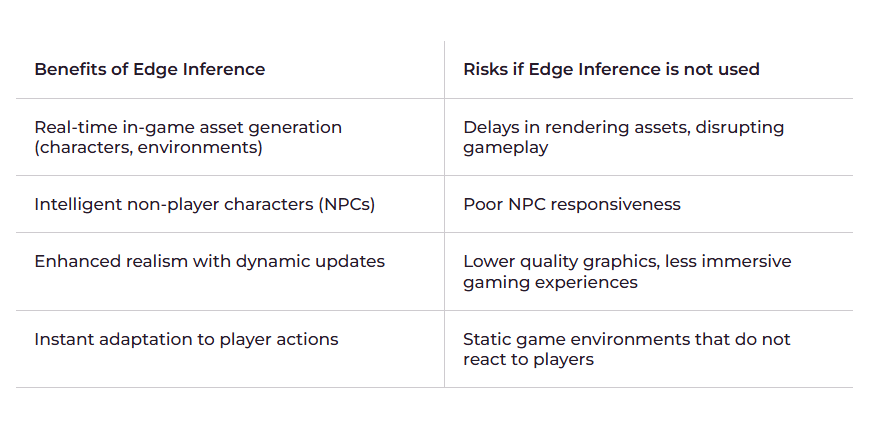
全球三分之一的人口都参与游戏,因此游戏行业致力于提供最身临其境、响应最快的体验也就不足为奇了。一项制胜的前沿人工智能应用是实时生成游戏内资产,例如角色、环境和 UI 元素。
挑战
高质量游戏资产生成面临两大挑战:
- 它们的创作十分耗时。
- 它们可能会给游戏玩家带来延迟。
随着用户对速度更快、内容更复杂和多样化的需求,游戏开发商面临着提供沉浸式游戏体验的压力。这需要大量的人力资源,推高了游戏成本,并给开发团队带来了繁重的工作安排。即使人工智能已经准备就绪,云处理也可能导致延迟问题,从而影响玩家的体验。
解决方案
边缘 AI 可以轻松改善延迟。通过将推理移到更靠近游戏玩家的位置,与传统的云推理相比,它们可以获得更快的响应时间。游戏可以通过边缘 AI 实时适应游戏玩家的决定。当玩家进入新区域或完成挑战时,AI 会动态创建新的景观、结构和交互元素,使游戏世界更具响应性和沉浸感。
在开发过程中使用边缘推理可以减轻开发人员创建大量复杂资产的压力:
- 生成式人工智能和大型语言模型(LLM) 可以简化叙事生成、对话系统和玩家支持,从而提高整体游戏质量和玩家参与度。
- 强化学习算法可以通过学习现实世界的动作捕捉数据来训练虚拟角色执行动作。这可以创建栩栩如生的动画,增强游戏的真实感。检索增强生成 (RAG) 还可用于优化 LLM 输出,方法是在生成响应之前引用知识库,以确保准确性和相关性。
现实生活中的例子:《Pokémon》中的 RAG
Pokémon 游戏中用于让玩家与了解 Pokémon 宇宙的智能助手进行互动。当玩家询问有关 Pokémon 的信息时,RAG 会搜索数据库以查找准确的详细信息,然后再生成响应。这意味着,如果玩家想了解 Bulbasaur 的动作,助手会从游戏数据中检索准确的信息并做出准确响应,从而增强玩家的知识和策略。使用边缘 AI 可以优化向玩家提供这些信息的速度。通过这种方式,游戏可以确保助手提供准确且相关的信息,让玩家更容易“抓住一切”,享受更加身临其境且信息丰富的游戏体验。
结果
利用边缘 AI 实时生成资产可确保游戏流畅、不间断,并可立即获得反馈。边缘 AI 可使游戏体验更具互动性、响应性更强、更个性化,从而提高玩家满意度并延长游戏时间。
边缘人工智能对视频娱乐产生巨大影响
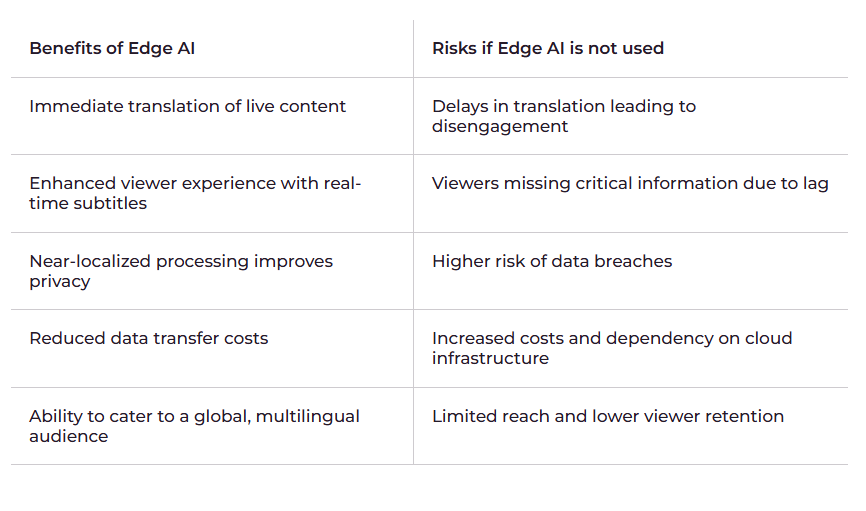
媒体和娱乐行业价值超过2.5 万亿美元,增长轨迹稳定,服务于希望零延迟、零停机、零限制地享受娱乐的全球观众。边缘 AI 可以改善全球媒体市场内容的一种方式是自动进行实时转录和翻译,实时提供字幕和副标题。这项技术有可能显著提高参与度:
- 如果有字幕,80%的观众更有可能观看完整视频
- 69% 的观众在公共场所选择关闭视频声音
- 50% 的消费者总是喜欢在关闭声音的情况下观看 UGC 视频内容
采用字幕和字幕的企业将占据更大的市场份额,如果加上自动翻译,则可以扩大其覆盖全球的影响力。
挑战
在传统的媒体发行中,转录和翻译都是由人工创建并在发布之前添加的。但今天,视频制作的纯粹数量和直播的盛行带来了两个挑战:
- 实现转录和翻译自动化,以最大限度地减少对人力资源的需求,并使这些功能的使用更加民主化
- 尽量减少延迟,使字幕与直播视频内容保持一致
基于云的翻译方法通常面临高成本和延迟问题,影响用户参与度和满意度。延迟意味着观众在直播活动中错过及时内容,导致观看体验不连贯且不满意。
解决方案
Edge AI 可以提供实时转录和翻译。这些模型在海量语言数据集和自然语言处理技术上进行训练,以准确理解和翻译内容。
这些模型无需在云端处理音频和视频流并处理延迟问题,而是在地理位置靠近观众的边缘接入点上运行。这种方法使平台能够生成与原始视频或直播视频同步的实时字幕和配音。
结果
边缘推理意味着翻译会在视频内容播放时几乎实时生成和显示,让观众能够立即了解正在发生的事情而不会错过任何一个节拍。当观众可以轻松地以自己的语言关注内容时,他们更有可能保持参与度和满意度。这种改进的体验可以提高观众的留存率并减少订阅取消率。
边缘AI助力高效客户服务
AI 有可能将客户服务成本降低高达 30% ,使其成为各行各业公司都青睐的解决方案。Gen AI 已经在此用例中证明了其价值。它可以通过聊天机器人和虚拟助手提供客户服务。
挑战
科技公司努力提供高质量的人工智能客户支持:
- 基于云的系统的延迟问题可能会延迟响应,从而让客户感到沮丧。
- 管理大量查询需要大量资源,从而增加运营成本。
- 旧版 AI 模型存在一些局限性,例如解释不准确,需要人工干预。
公司需要一种有效的解决方案来提供即时支持、处理复杂的查询并管理不断增长的客户需求,同时又不会花费太多。
解决方案
由于边缘 AI 靠近客户运行,因此它可以近乎实时地做出响应。这与传统的基于云的系统相比是一个重大升级,后者的响应时间可能长达 500 毫秒。
边缘人工智能可以为高级虚拟助手和聊天机器人提供支持,提供全天候支持并减少人工干预。边缘人工智能推理系统可以支持在必要时将复杂查询升级到人工代理的模型,确保准确高效地处理复杂问题。
结果
在靠近客户的地方处理数据可确保查询几乎立即得到处理。与较慢的云推理或等待人工代理相比,这大大改善了客户支持体验。它还使企业能够全天候获得高质量的客户支持,使企业能够即时为全球客户提供服务。
使用人工智能自动执行日常客户服务任务可减少人工客服的工作量,使他们能够专注于更复杂的问题。这还可以通过减少对大量人力资源的需求来大幅节省成本
将数据保存在更接近使用地点的地方可以降低泄露风险,从而提高安全性,因为个人数据不需要传输到远程服务器。这对于可能需要在客户服务互动过程中请求个人信息的零售公司来说是一个很大的好处。
利用边缘的 Gcore 推理来促进您的业务
边缘推理为边缘 AI 提供支持。该服务在 95 多个国家/地区设有 180 多个接入点,让 AI 推理更贴近您的用户,从而减少延迟并为实时 AI 应用程序提供超快速响应。我们管理所有基础设施,因此您可以轻松享受边缘推理带来的业务提升。
使用 Gcore Inference at the Edge 可获得以下好处:
- 灵活的模型部署:轻松运行开源模型、微调专属模型或部署自定义模型。无论您是使用预训练模型还是创建新模型,您都可以选择最适合您需求的方法。
- 强大的 GPU 基础设施:使用专为 AI 推理设计的NVIDIA L40S GPU提升您的模型性能。这些 GPU 可用作专用实例或无服务器端点,为您提供高效处理复杂 AI 工作负载所需的能力。
- 低延迟全球网络:凭借超过 180 个战略位置的边缘接入点 (PoP) 和仅 30 毫秒的平均网络延迟,我们确保您的 AI 应用程序能够快速响应,无论您的用户位于世界何处。
- 单一端点实现全局推理:无缝集成模型到应用程序中,轻松实现基础设施管理自动化。我们的单一端点简化了部署,让全球 AI 解决方案的管理和扩展变得简单易行。
- 模型自动扩展:我们的基础设施会根据用户需求动态扩展,因此您只需为使用的计算能力付费。这可以帮助您管理成本,同时确保您始终拥有满足需求所需的资源。
- 安全性和合规性:受益于集成的DDoS 保护和GDPR、 PCI DSS和 ISO/IEC 27001 标准的合规性。我们确保您的数据和应用程序安全并满足最高监管要求。
如果您已准备好转换 AI 工作负载,请考虑使用 Gcore Inference at the Edge。